由TCGA代码部分演变而来
1. 数据下载
proj = "GSE150392" #可以套用在其他代码里面了
1. 生存信息与临床信息
这里仅仅是查看一下生存信息等样品临床表型信息,到生存信息部分再整理。
library(GEOquery)
eSet = getGEO("GSE150392",destdir = ".",getGPL = F)
eSet = eSet[[1]]
exp = exprs(eSet)
pd = pData(eSet)
1. 表达矩阵行名ID转换
dat = read.csv("GSE150392_Cov_Mock_Raw_COUNTS.csv.gz",
row.names = 1)
exp = dat
library(stringr)
library(dplyr)
#行名ID转换:方法1(推荐)
head(rownames(exp))
x = !str_starts(rownames(exp),"ERCC");table(x)
exp = exp[x,]
b = rownames(exp) %>%
str_replace("_","///") %>% #因为这个数据的基因中有_,所以将第一个下划线改为///,方便后续的切割
str_split("///",simplify = T) #这一步骤很重要
k = !duplicated(b[,2]);table(k) #如果重复,则返回false,不重复则返回true
exp = exp[k,] #表达矩阵中筛选只返回ture的行
b = b[k,] #也是筛选返回true的行,值和exp对应的
rownames(exp) = b[,2]
exp = as.matrix(exp)
###可供参考
# b1 = rownames(exp) %>%
# str_replace("_","///") %>%
# str_split("///",simplify = T) %>% .[,2]
# b1 = !duplicated(b1)
1. 基因过滤
需要过滤一下那些在很多样本里表达量都为0或者表达量很低的基因。过滤标准不唯一。
过滤之前基因数量:
nrow(exp)
常用过滤标准1:
仅去除在所有样本里表达量都为零的基因
exp1 = exp[rowSums(exp)>0,]
nrow(exp1)
常用过滤标准2(推荐):
仅保留在一半以上样本里表达的基因
exp = exp[apply(exp, 1, function(x) sum(x > 0) > 0.5*ncol(exp)), ]
nrow(exp)
1. 分组信息获取
Group = str_remove(colnames(exp),"\\d") #将列名中的数字删除,成为了两个分组
Group = factor(Group,levels = c("Mock","Cov")) #对照组在前,实验组在后
table(Group)

1. 保存数据
save(exp,Group,proj,file = paste0(proj,".Rdata"))
1. 三大R包差异分析
DESeq2和edgeR和limma三大包
rm(list = ls())
load("GSE150392.Rdata")
table(Group)
#deseq2----
library(DESeq2)
colData <- data.frame(row.names =colnames(exp),
condition=Group)
if(!file.exists(paste0(proj,"_dd.Rdata"))){
dds <- DESeqDataSetFromMatrix(
countData = exp,
colData = colData,
design = ~ condition)
dds <- DESeq(dds)
save(dds,file = paste0(proj,"_dd.Rdata"))
}
load(file = paste0(proj,"_dd.Rdata"))
class(dds)
res <- results(dds, contrast = c("condition",rev(levels(Group))))
#constrast
c("condition",rev(levels(Group)))
class(res)
DEG1 <- as.data.frame(res)
DEG1 <- DEG1[order(DEG1$pvalue),]
DEG1 = na.omit(DEG1)
head(DEG1)
#添加change列标记基因上调下调
logFC_t = 2
pvalue_t = 0.05
k1 = (DEG1$pvalue < pvalue_t)&(DEG1$log2FoldChange < -logFC_t);table(k1)
k2 = (DEG1$pvalue < pvalue_t)&(DEG1$log2FoldChange > logFC_t);table(k2)
DEG1$change = ifelse(k1,"DOWN",ifelse(k2,"UP","NOT"))
table(DEG1$change)
head(DEG1)
#edgeR----
library(edgeR)
exp = na.omit(exp)
dge <- DGEList(counts=exp,group=Group)
dge$samples$lib.size <- colSums(dge$counts)
dge <- calcNormFactors(dge)
design <- model.matrix(~Group)
dge <- estimateGLMCommonDisp(dge, design)
dge <- estimateGLMTrendedDisp(dge, design)
dge <- estimateGLMTagwiseDisp(dge, design)
fit <- glmFit(dge, design)
fit <- glmLRT(fit)
DEG2=topTags(fit, n=Inf)
class(DEG2)
DEG2=as.data.frame(DEG2)
head(DEG2)
k1 = (DEG2$PValue < pvalue_t)&(DEG2$logFC < -logFC_t);table(k1)
k2 = (DEG2$PValue < pvalue_t)&(DEG2$logFC > logFC_t);table(k2)
DEG2$change = ifelse(k1,"DOWN",ifelse(k2,"UP","NOT"))
head(DEG2)
table(DEG2$change)
###limma----
library(limma)
dge <- edgeR::DGEList(counts=exp)
dge <- edgeR::calcNormFactors(dge)
design <- model.matrix(~Group)
v <- voom(dge,design, normalize="quantile")
design <- model.matrix(~Group)
fit <- lmFit(v, design)
fit= eBayes(fit)
DEG3 = topTable(fit, coef=2, n=Inf)
DEG3 = na.omit(DEG3)
k1 = (DEG3$P.Value < pvalue_t)&(DEG3$logFC < -logFC_t);table(k1)
k2 = (DEG3$P.Value < pvalue_t)&(DEG3$logFC > logFC_t);table(k2)
DEG3$change = ifelse(k1,"DOWN",ifelse(k2,"UP","NOT"))
table(DEG3$change)
head(DEG3)
tj = data.frame(deseq2 = as.integer(table(DEG1$change)),
edgeR = as.integer(table(DEG2$change)),
limma_voom = as.integer(table(DEG3$change)),
row.names = c("down","not","up")
);tj
save(DEG1,DEG2,DEG3,Group,tj,file = paste0(proj,"_DEG.Rdata"))
可视化
使用了生信技能树老师的包:tinyarray
这个包里可以画pca,热图,火山图,韦恩图,具体每个图的算法,可以看生信技能树GEO芯片分析
library(ggplot2)
library(tinyarray)
exp[1:4,1:4]
# cpm去除文库大小的影响
dat = log2(cpm(exp)+1) # dat为使用count数据转化而成的cpm数据,使用这个数据画图,而count数据只是用来做差异分析
pca.plot = draw_pca(dat,Group);pca.plot
save(pca.plot,file = paste0(proj,"_pcaplot.Rdata"))
cg1 = rownames(DEG1)[DEG1$change !="NOT"]
cg2 = rownames(DEG2)[DEG2$change !="NOT"]
cg3 = rownames(DEG3)[DEG3$change !="NOT"]
h1 = draw_heatmap(dat[cg1,],Group,n_cutoff = 2)
h2 = draw_heatmap(dat[cg2,],Group,n_cutoff = 2)
h3 = draw_heatmap(dat[cg3,],Group,n_cutoff = 2)
v1 = draw_volcano(DEG1,pkg = 1,logFC_cutoff = logFC_t)
v2 = draw_volcano(DEG2,pkg = 2,logFC_cutoff = logFC_t)
v3 = draw_volcano(DEG3,pkg = 3,logFC_cutoff = logFC_t)
library(patchwork)
(h1 + h2 + h3) / (v1 + v2 + v3) +plot_layout(guides = 'collect') &theme(legend.position = "none")
ggsave(paste0(proj,"_heat_vo.png"),width = 15,height = 10)



三大R包差异基因对比
UP=function(df){
rownames(df)[df$change=="UP"]
}
DOWN=function(df){
rownames(df)[df$change=="DOWN"]
}
up = intersect(intersect(UP(DEG1),UP(DEG2)),UP(DEG3))
down = intersect(intersect(DOWN(DEG1),DOWN(DEG2)),DOWN(DEG3))
dat = log2(cpm(exp)+1)
hp = draw_heatmap(dat[c(up,down),],Group,n_cutoff = 2)
#上调、下调基因分别画维恩图
up_genes = list(Deseq2 = UP(DEG1),
edgeR = UP(DEG2),
limma = UP(DEG3))
down_genes = list(Deseq2 = DOWN(DEG1),
edgeR = DOWN(DEG2),
limma = DOWN(DEG3))
up.plot <- draw_venn(up_genes,"UPgene")
down.plot <- draw_venn(down_genes,"DOWNgene")
#维恩图拼图,终于搞定
library(patchwork)
#up.plot + down.plot
#拼图
pca.plot + hp+up.plot +down.plot+ plot_layout(guides = "collect")
ggsave(paste0(proj,"_heat_ve_pca.png"),width = 15,height = 10)



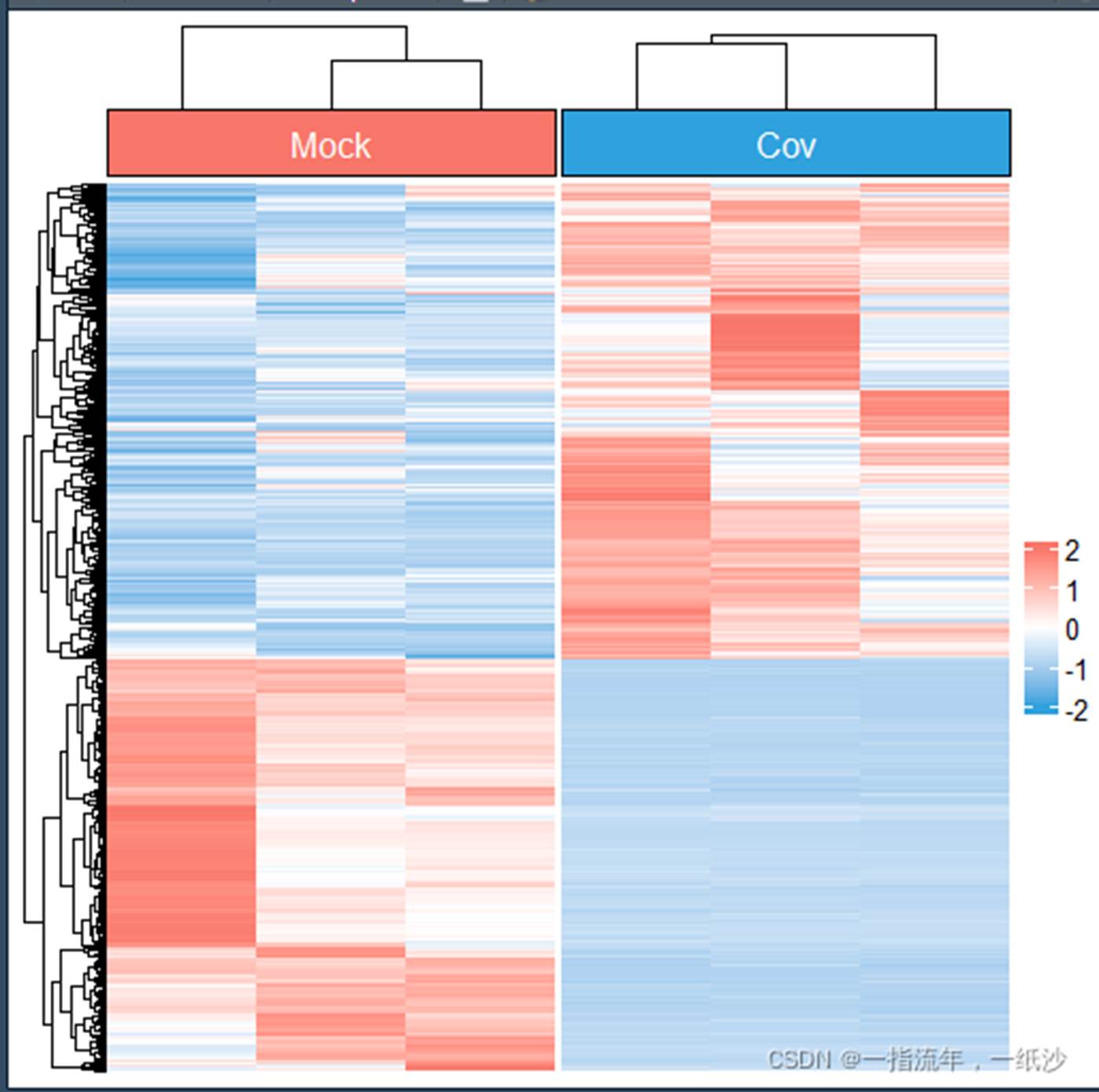
 分组聚类的热图
分组聚类的热图
library(ComplexHeatmap)
library(circlize)
col_fun = colorRamp2(c(-2, 0, 2), c("#2fa1dd", "white", "#f87669"))
top_annotation = HeatmapAnnotation(
cluster = anno_block(gp = gpar(fill = c("#f87669","#2fa1dd")),
labels = levels(Group),
labels_gp = gpar(col = "white", fontsize = 12)))
m = Heatmap(t(scale(t(exp[c(up,down),]))),name = " ",
col = col_fun,
top_annotation = top_annotation,
column_split = Group,
show_heatmap_legend = T,
border = F,
show_column_names = F,
show_row_names = F,
use_raster = F,
cluster_column_slices = F,
column_title = NULL)
m
转载自《生信技能树》,如有侵权,请联系删除。

