本文由医信融合团队成员“陈浩然”撰写,已同步至微信公众号“医信融合创新沙龙”与“研究生学生信”,更多精彩内容欢迎关注!


前言
一个人如果认为意外是对个人的侮辱,那意味永远不会找上他。一个人如果把一切都归结为意外,那他永远就不会鼓起勇气和生活抗争。
——吸奇侠
首先推荐:
果子老师的公众号
以及本文参考的推送
资源!GEO芯片分析教程汇总。
30分钟的教程写了13年,被名字耽误的正则表达式!
GEO芯片中的NM,NR开头的识别号如何转换成基因名称?
有些GEO平台的探针转换比较麻烦
如何让基因名称在多个数据库间随意转换?
如果不太清楚如何挖掘GEO数据库的,可以先看
1.四文搞定GEO数据库转录组差异分析之简介
2.四文搞定GEO数据库转录组差异分析之操作
1
本文能解决的问题
在我们分析GEO数据的时候,总会遇到下面这样的GPL,没有gene symbol,也不太好转换。参考GEO芯片中的NM,NR开头的识别号如何转换成基因名称?等其他ID转换的文章,我们确实是可以完成任务,但是特别费时费力,而且总是得一种ID对应一种转换流程,很麻烦。
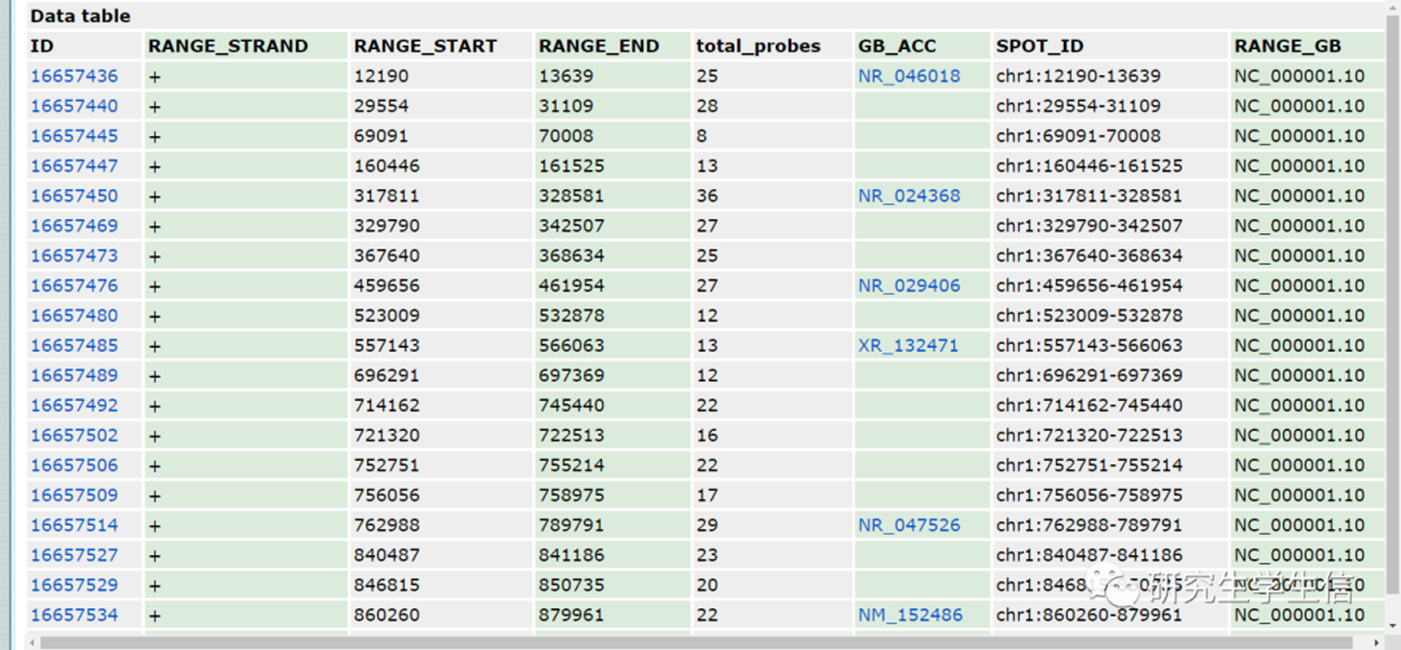
当需要分析10个平台的时候,我们可能一个一个做,3天能做完,而如果当我们需要分析6000个平台的时候。。。

本文主要针对没有symbol列的人/小鼠的芯片数据GPL文件进行自动、批量ID转换,对着电脑发会儿呆,GPL文件就处理好了。
2
主要利用俩技术
正则表达式负责识别ID类型以及具体的每个ID
bioma**Rt**包负责各种ID转换
3
怎么用
1. 2022年6月23日之前,后台回复GEO芯片分析,获取相关代码和文件
2. 打开GPL_auto_ann.Rproj
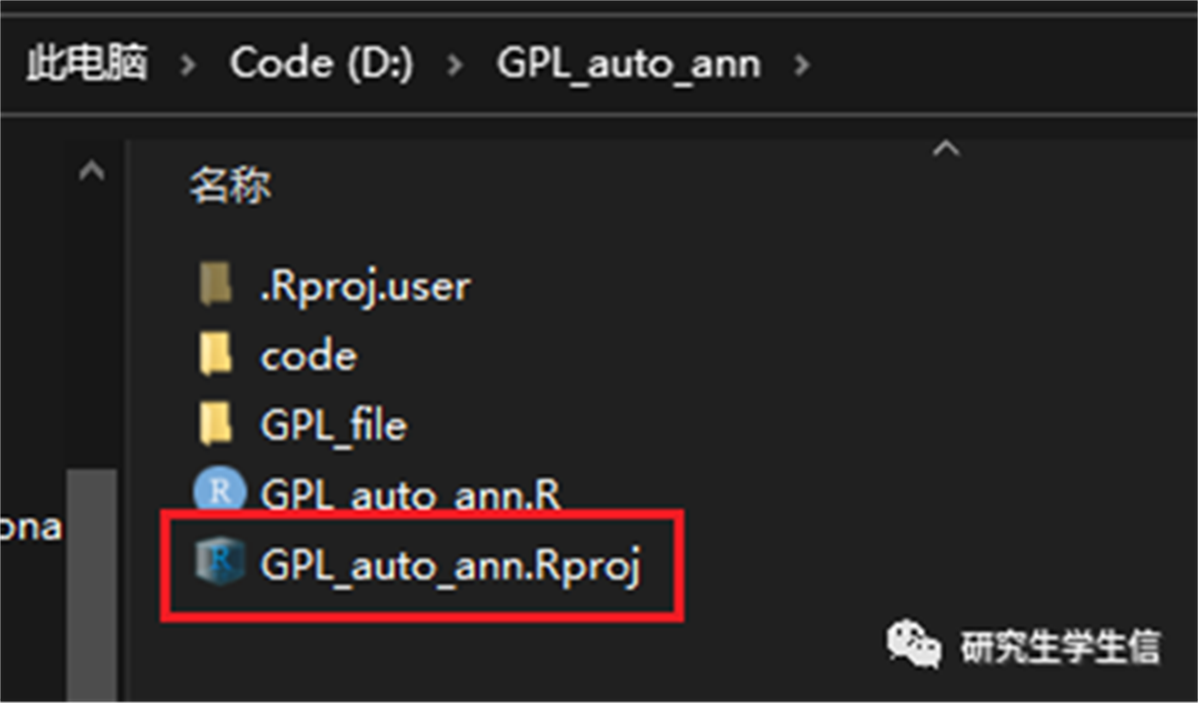
3. 在Rstudio的右下窗口File栏中双击GPL_auto_ann.R
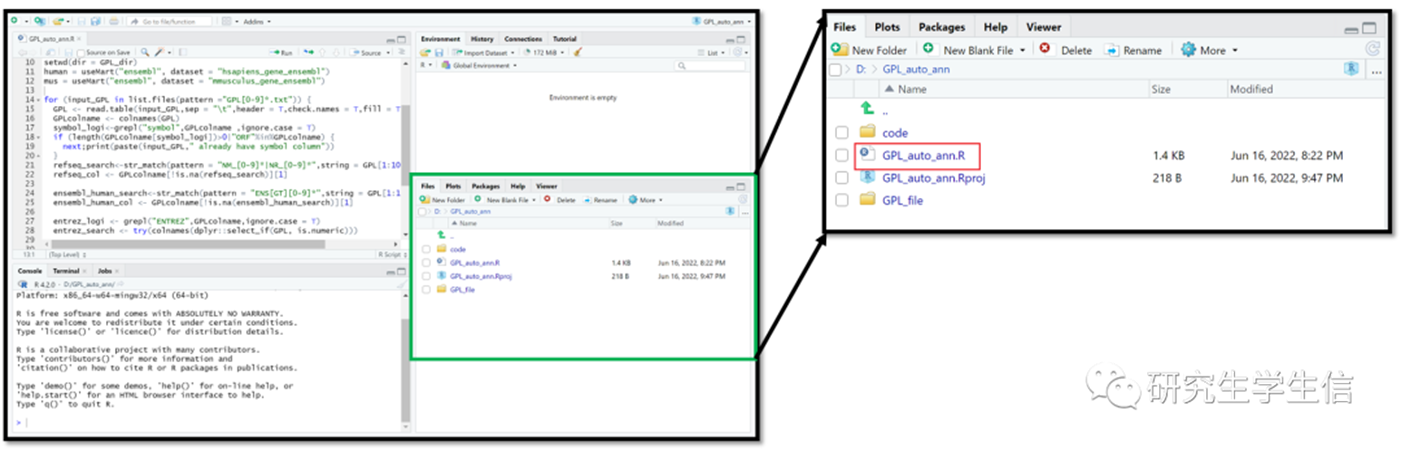
4. 修改第三行root_dir的目录名为GPL_auto_ann文件夹所在目录,以“/”斜杠分割,如此处为D:/GPL_auto_ann
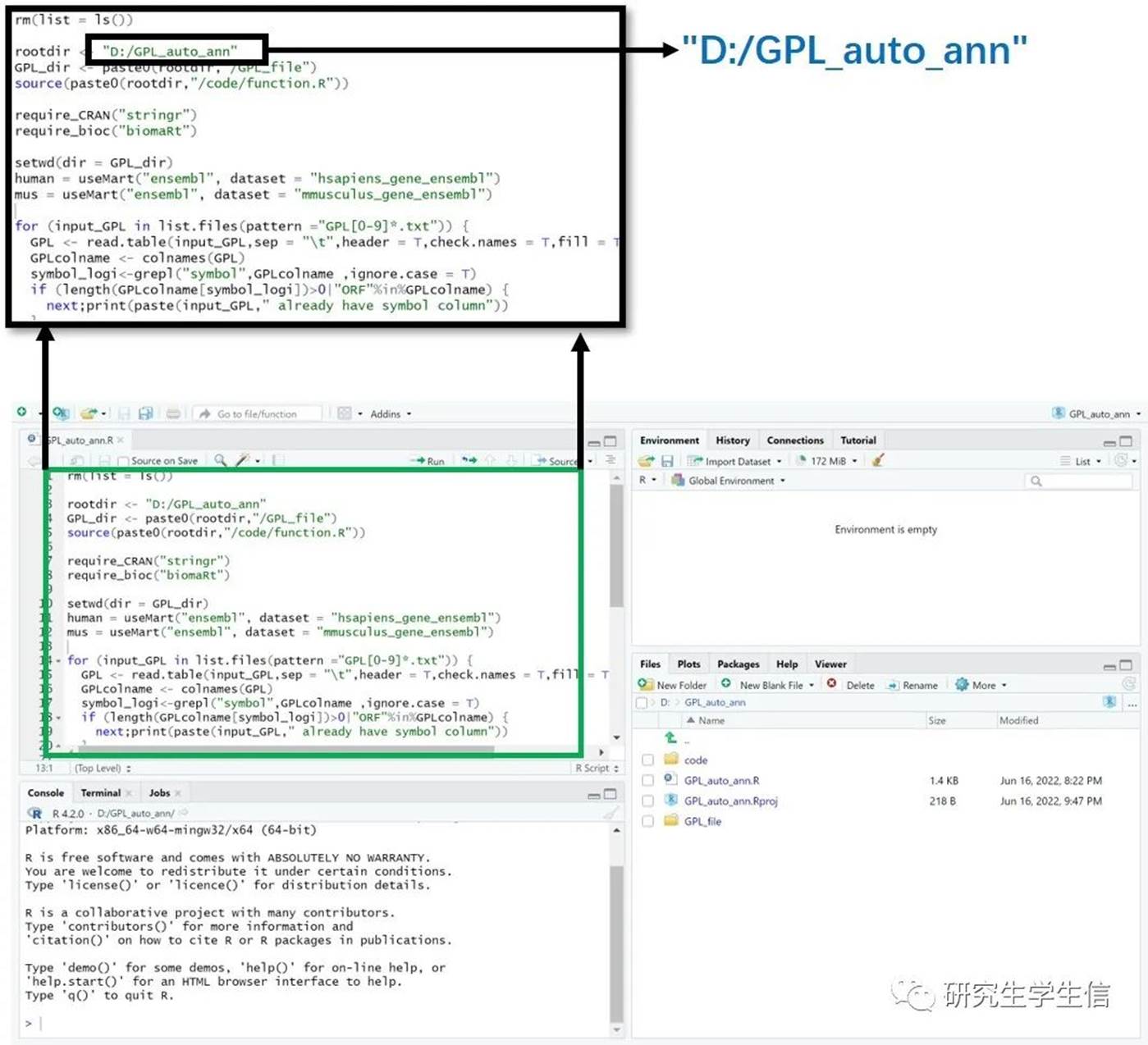
5. 将需要ID转换的GPL文件放入GPL_file文件夹
6. Rstudio左上区域ctrl+A全选代码,然后
 即可
即可
一些声明:
• 本文并未针对大鼠ID转换写相应代码,请运行之前检查!
• 由于GPL文件现在挺大的,因此输出文件将覆盖源文件,并仅保留两列(ID列和symbol列)
• 针对原来就已经有symbol列的GPL文件,代码并未做任何修改
感谢观看到最后,敬请批评指正

图文:陈浩然
本文编辑:莫状

