贾文辉等基于机器学习算法构建了脑梗死后出血转化预测模型及进行相关危险因素研究
脑梗死后出血转化(HT)是脑梗死最危险的并发症。HT是导致临床医疗事故纠纷常见原因,同时因为临床医师和患者担心出血转化导致我国静脉溶栓率低、房颤抗凝药物使用率低、抗栓药物使用率低、患者不当停药等,严重阻碍脑梗死有效防治。所以能够早期发现识别HT危险预测因素,建立一种准确高效简易的预测量表模型将是我们防治脑梗死出血转化并发症,进行预防的有力工具。国外已经开发了一些HT预测模型,如溶血后出血评分(HAT评分)、溶栓后症状性脑出血评分模型(SITS-MOST评分)、 GRASPS症状性颅内出血预测评分、iScore预测模型等,以上各预测模型虽然各有优点,但都存在缺乏影像学资料、影像学新技术和血清标志物而预测效能差的问题,有必要建立一种全面准确的HT预测模型。
贾文辉等在临床研究中,针对数据处理和模型构建方面,患者信息呈现几何数量级增长、海量大数据的特点,脑梗死相关危险因素往往是信息量大、复杂多变,传统数据处理方法弊端显现,其无法解决数据之间非线性的问题,很难去拟合数据的真实分布,特别是数据量大、变量多、变量之间关系复杂呈共线等的情况下传统模型处理低效效能差,采用机器学习算法,为开展海量信息的挖掘分析,提供了有效的解决途径。机器学习并不需要事先对大量数据进行人工分析,然后提取规则并建立模型,而是提供了一种更为有效的方法来捕捉数据中的知识,逐步提高预测模型的性能,以完成数据驱动的决策。
机器学习模型中,LR是机器学习中的一种基于概率的分类算法,属于监督学习技术,是一种使用逻辑函数对条件概率进行建模的统计模型。RF是集成学习Bagging算法当中的典型代表,它使用了CART决策树作为基学习器,结合自助采样法从总体样本当中随机取一部分样本进行训练,通过多次这样的抽取来并行化训练许多棵决策树,并将多棵决策树的预测结果整合起来使用,这样使得最终集成模型具有很强的泛化能力,并且能够降低模型的方差。AdaBoost算法属于集成学习Boosting算法中的一种,模型的训练过程是不断迭代提升的,每一个基分类器都是根据前一个基分类器的预测结果,增加分类错误样本集合的权重,减小分类正确样本集合的权重,以此来提升模型的泛化能力。XGBoost算法是集成学习Boosting算法中的一种,它是通过新加入的基分类器进一步拟合预测值与真实值之间的差异,同时XGBoost在损失函数中加入正则化项,并对损失函数进行二阶泰勒展开,以减少过拟合的可能,并加快模型的收敛速度。SVM是由Cortes和Vapkin 在统计学习理论的基础上提出的一种机器学习方法[6]。它的基本思想是找到一个能够满足分类要求的最大间隔超平面,并且在保证分类精度的情况下,最大化该分类面两侧的空白区域。SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务,在医疗诊断、图像识别、文本分类等有着非常广泛的应用。
在机器学习中,采用混淆矩阵(Confusion Matrix)作为分类问题的性能评价指标,混淆矩阵又称为可能性矩阵,在无监督学习中一般叫做匹配矩阵,通过混淆矩阵,能够直观地看出模型对每个类别的预测情况。常用的指标有精确度、准确度、特异度、灵敏度、约登指数。(模型技术路线图见图1)。
图1 预测模型技术路线图

在研究中对脑梗死后出血转化的66个变量进行单因素比较后,将28项代入机器学习算法预测模型进行筛选变量和模型评价,结果如下:
研究结果1 LR模型筛选结果
将筛选出来的28个变量作为特征,是否发生脑梗死出血转化作为标签输入到LR模型。从Scikit-Learn库导入Logistic Regression模块构建LR模型,在训练集上对模型进行训练,在测试集上对训练好的模型进行性能评估。此外LR对HT风险因素进行筛选重要度排序,排名前10的是:NIHSS评分、入院舒张压、白蛋白、血红蛋白Hb、中心粒与淋巴细胞比值NLR、PT、双抗治疗、空腹血糖、脑微出血CMB、脑白质病变。模型预测结果为:精确度为0.73,准确度为0.70,灵敏度为0.80,特异度为0.67,约登指数为0.45,AUC为0.83。具体指标见下表1、图2。

图2 LR模型分析结果

研究结果2 RF模型筛选结果
将筛选出来的28个变量作为特征,是否发生HT作为标签输入到RF模型。从Scikit-Learn库导入Random Forest Classifier模块构建RF模型,在训练集上对模型进行训练,同时调用Grid SearchCV函数探索模型的最优超参数组合,采用5折交叉验证的方式,以“rocauc”作为模型评价标准,保存最优模型并在测试集上对模型进行评估。最优超参数组合:max_features=20,nestimators=100。此外,RF对脑梗死出血转化风险因素进行重要度筛选排序,排名前10的是:肌钙蛋白、BNP、白蛋白、CMB、NIHSS、大面积脑梗死LHI、NLR、D-二聚体、双抗治疗、尿酸。模型预测结果为:精确度为0.97,准确度为0.97,灵敏度为0.97,特异度为0.97,约登指数为0.93,AUC为0.97。具体指标见下表2、图3。
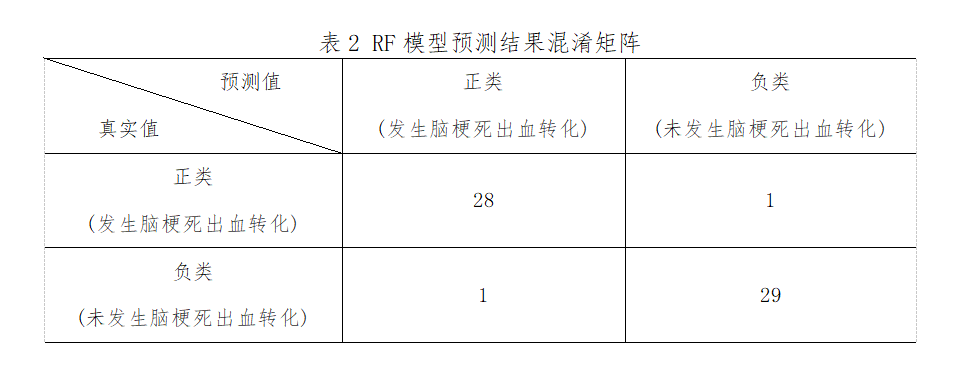
图3 RF模型分析结果

研究结果3 AdaBoos模型筛选结果
将筛选出来的28个变量作为特征,是否发生脑梗死出血转化作为标签输入到AdaBoost模型。从Scikit-Learn库导入AdaBoost Classifier模块构建AdaBoost模型,在训练集上对模型进行训练,同时调用GridSearchCV函数探索模型的最优超参数组合,采用5折交叉验证的方式,以“rocauc”作为模型评价标准,保存最优模型并在测试集上对模型进行评估。最优超参数组合:learning_rate=0.4,nestimators=300。此外,AdaBoost对HT风险因素进行重要度排序,排名前的是:肌钙蛋白、BNP、血糖、白蛋白、NLR、尿酸、脑白质病变WMH、双抗治疗、年龄、NIHSS。模型预测结果为:精确度为0.97,准确度为0.97,灵敏度为0.97,特异度为0.97,约登指数为0.93,AUC为0.99。具体指标见下表3、图4。

图4 AdaBoost模型预测结果

研究结果4 XGBoost模型筛选结果
将筛选出来的28个变量作为特征,是否发生脑梗死出血转化作为标签输入到XGBoost模型。从Scikit-Learn库导入XGBClassifier模块构建XGBoost模型,在训练集上对模型进行训练,同时,调用GridSearchCV函数探索模型的最优超参数组合,采用5折交叉验证的方式,以“roc_auc”作为模型评价标准,保存最优模型并在测试集上对模型进行评估。最优超参数组合:colsample_bytree=0.6,learning_rate=0.01,max_depth=2,min_child_weight=1, nestimators=100, subsample=0.9。此外,XGBoost对脑梗死出血转化风险因素进行重要度排序,排名前10的是:肌钙蛋白、BNP、CMB、LHI、静脉溶栓、NIHSS、双抗治疗、NLR、D-二聚体、尿酸。模型预测结果为:精确度为0.98,准确度为0.97,灵敏度为1.00,特异度为0.97,约登指数为0.97,AUC为0.99。具体指标见下表4、图5。
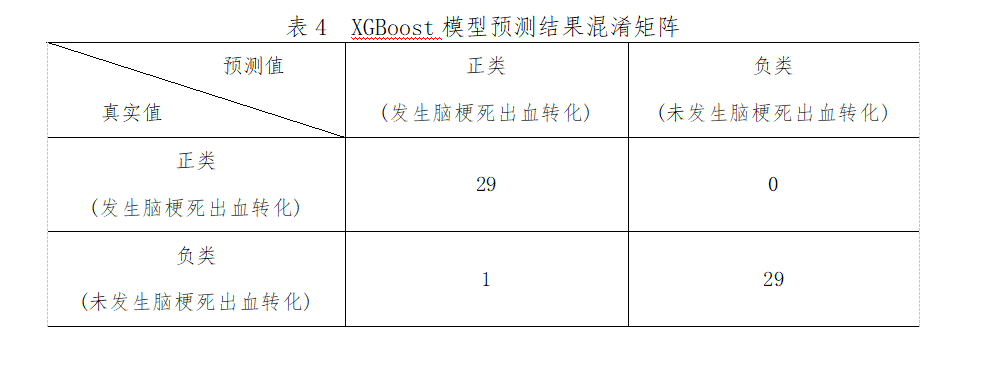
图5 XGBoost模型预测结果

研究结果5 SVM模型筛选结果
将筛选出来的28个变量作为特征,是否发生脑梗死出血转化作为标签输入到SVM模型。从Scikit-Learn库导入svm模块构建SVM模型,选取核函数为线性核函数,在训练集上对模型进行训练,同时,调用GridSearchCV函数探索模型的最优超参数组合,采用5折交叉验证的方式,以“roc_auc”作为模型评价标准,保存最优模型并在测试集上对模型进行评估。在kernel为最优超参数组合:C=8,gamma=0.01。此外,SVM对HT风险因素进行重要度筛选排序,排名前10的是:CMB、WMH、蛋白尿、房颤、LHI、双抗治疗、国际标准化比值INR、红细胞RBC、TG、白细胞WBC。模型预测结果为:精确度为0.71,准确度为0.70,灵敏度为0.72,特异度为0.70,约登指数为0.42,AUC为0.82。具体指标见下表5、图6。

图6 SVM模型预测结果

研究结果6 各种机器学习模型结果比较
五个模型各项指标均显示良好,其中RF、AdaBoost、XGBoost表现更佳,精确度、准确度、特异度、灵敏度均在0.97以上,AUC为0.97 ,显示出对HT很好的预测性能预测;单个模型中XGBoost模型的灵敏度最高;AdaBoost和XGBoost模型的AUC最高。而LR和SVM表现一般,具体指标见下表6、图7
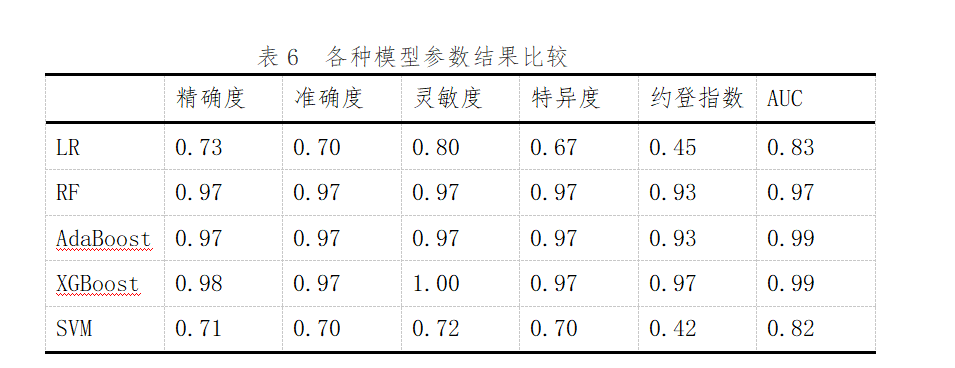
图7 各种模型结果比较ROC曲线

研究结果7 脑梗死后出血转化联合预测模型构建结果
根据机器学习算法预测模型筛选因素结合专业方面最终选择NIHSS、NLR、双抗治疗、WMH、LHI、年龄、静脉溶栓、CMB、空腹血糖9项变量进行多因素建模分析,最终除年龄外8项变量进入模型建立Logistic多因素回归预测模型,灵敏度为91.9% 特异度为98.8%,阳性似然比110.385,联合预测模型ROC曲线AUC为0.918,P<0.05。见表7、8,图8。
表7 脑梗死后出血转化logistic回归模型
变量 |
回归系数 |
标准误 |
OR值(95%置信区间) |
P值 |
常量 |
-6.454 |
1.175 |
- |
- |
NIHSS |
0.150 |
0.053 |
1.163(1.047,1.290) |
0.005* |
NLR |
0.164 |
0.074 |
1.178(1.019,1.361) |
0.027* |
双抗治疗 |
1.107 |
0.551 |
3.026(1.028,8.909) |
0.045* |
WMH |
1.680 |
0.673 |
5.363(1.433,20.067) |
0.013* |
LHI |
1.552 |
0.622 |
4.722(1.396,15.977) |
0.041* |
静脉溶栓 |
1.824 |
0.561 |
6.194(2.064,18.589) |
0.001* |
CMB |
1.647 |
0.625 |
5.193(1.527,17.633) |
0.008* |
空腹血糖 |
0.210 |
0.085 |
1.234(1.045,1.457) |
0.013* |
注:P<0.05为有统计学差异
表8 ROC曲线下的区域
检测项目 |
AUC |
标准误 |
P |
95%CI |
下限 |
上限 |
Y值 |
0.918 |
0.022 |
<0.001 |
0.875 |
0.961 |
Y值= NIHSS+NLR+双抗治疗+WMH+LHI+静脉溶栓+CMB+空腹血糖
脑梗死后出血转化多因素风险预测模型方程为:

X1= NIHSS X2= NLR X3=双抗治疗X4=WMH X5=LHI X6=静脉溶栓X7=CMB X8=空腹血糖
图8 HT多因素预测模型结果ROC曲线

综上所述,我们在本研究中对66项变量进行单因素筛选后,筛选出年龄、INR、MWH、BNP、CMB等28项变量进入机器学习模型中,经模型训练验证后发现大部分变量均表现良好,机器学习算法LR、RF、AdaBoost、XGBoost及SVM5个模型筛选出年龄、NIHSS、静脉溶栓、双抗治疗、WMH、LHI、CMB、NLR及空腹血糖为HT独立危险因素;在预测HT方面,LR、RF、Ada Boost、XGBoost以及SVM5个机器学习模型表现均良好,RF、AdaBoost、XGBoost表现更佳;最后建立的脑梗死出血转化多因素预测模型同时包含了临床、生物学和影像学因素,预测效能方面较其他模型更加全面准确,对于临床有很大的指导预测意义。肌钙蛋白、BNP、低水平尿酸为HT潜在危险因素。
本研究主要研究者为山西医科大学第一临床医学院博士贾文辉,指导教师为李常新教授,共同研究者为太原理工大学信息与计算机学院李凤莲教授、杜鹏、谢静,大连医科大学公共卫生学院雷芳等。本课题受到国家自然基金合作项目“强化学习视域下的脑卒中多模态数据集成学习优化算法及发病风险预测研究(No.62171307)”和山西省人民医院省级专项配套项目基金“脑卒中大数据相关风险预测模型研究(No.sj20019007)”资助。

